
How Python read or write files under the hood
Python makes users easy to operate files by hiding the implementation details for the IO module. This article aim in discourse more details about how it works for people who want to know more about it.
The code
From PEP 399
The purpose of this PEP is to minimize this duplicate effort by mandating that all new modules added to Python’s standard library must have a pure Python implementation unless special dispensation is given.
We can find the code in IO module in Modules/_io/_iomodule.c as well as Lib/pyio.py.
Python 2 and Python 3
In Python 2, we use FILE streams (i.e. fopen, fclose, fread) for performance optimization. However, since The python community wants to be more reliably cross-platform than C FILE streams. Python 3 implements its user space cache (i.e. write buffer and read buffer). If you are not familiar with cache, you may have a look at cache. There are three main types of I/O (Text, Binary, Raw). Python 3 still uses FILE streams library internally in some cases (e.g. to read pyvenv.cfg at startup), (Thanks eryk sun).
Open files
Open file is the first thing we need to do before reading or writing files. Before we actually call the system call open(), we have to do some configure depend on the input parameters. For instance, the buffering arg from the build-in open() function:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
buffering is an optional integer used to set the buffering policy. Pass 0 to switch buffering off (only allowed in binary mode), 1 to select line buffering (only usable in text mode), and an integer > 1 to indicate the size in bytes of a fixed-size chunk buffer. When no buffering argument is given, the default buffering policy works as follows:
Binary files are buffered in fixed-size chunks; the size of the buffer is chosen using a heuristic trying to determine the underlying device’s “block size” and falling back on io.DEFAULT_BUFFER_SIZE. On many systems, the buffer will typically be 4096 or 8192 bytes long.
“Interactive” text files (files for which isatty() returns True) use line buffering. Other text files use the policy described above for binary files.
Moreover, different kinds of open mode will return different objects:
| IO | Object |
|---|---|
| Text I/O | TextIOWrapper |
| Binary I/O | BufferedReader / BufferedWriter / BufferedRandom |
| Raw I/O | FileIO |
# Operate the file with text mode
>>> textio = open('example.py', 'r')
>>> type(textio)
<class '_io.TextIOWrapper'>
# Operate the file with binary mode
>>> binaryio = open('example.py', 'rb')
>>> type(binaryio)
<class '_io.BufferedReader'>
>>> binaryio = open('example.py', 'wb')
>>> type(binaryio)
<class '_io.BufferedWriter'>
# set buffering=0
>>> fileio = open("example.py", "rb", buffering=0)
>>> type(fileio)
<class '_io.FileIO'>
Both of Text I/O and Binary I/O has their read buffer and write buffer (bytearray). The difference between them is Text I/O (TextIOWrapper object) is a wrapper on Binary I/O. It will do some extra job (i.e try to encode the string to bytes at first) before operating the data. For example, in the TextIOWrapper read() function
result = (self._get_decoded_chars() + decoder.decode(self.buffer.read(), final=True))
Text I/O will call self.buffer.read() which is handled by Binary I/O after encoding/decoding.
Text I/O and Binary I/O Read
Both of them did very similar jobs in Reading and Writing:
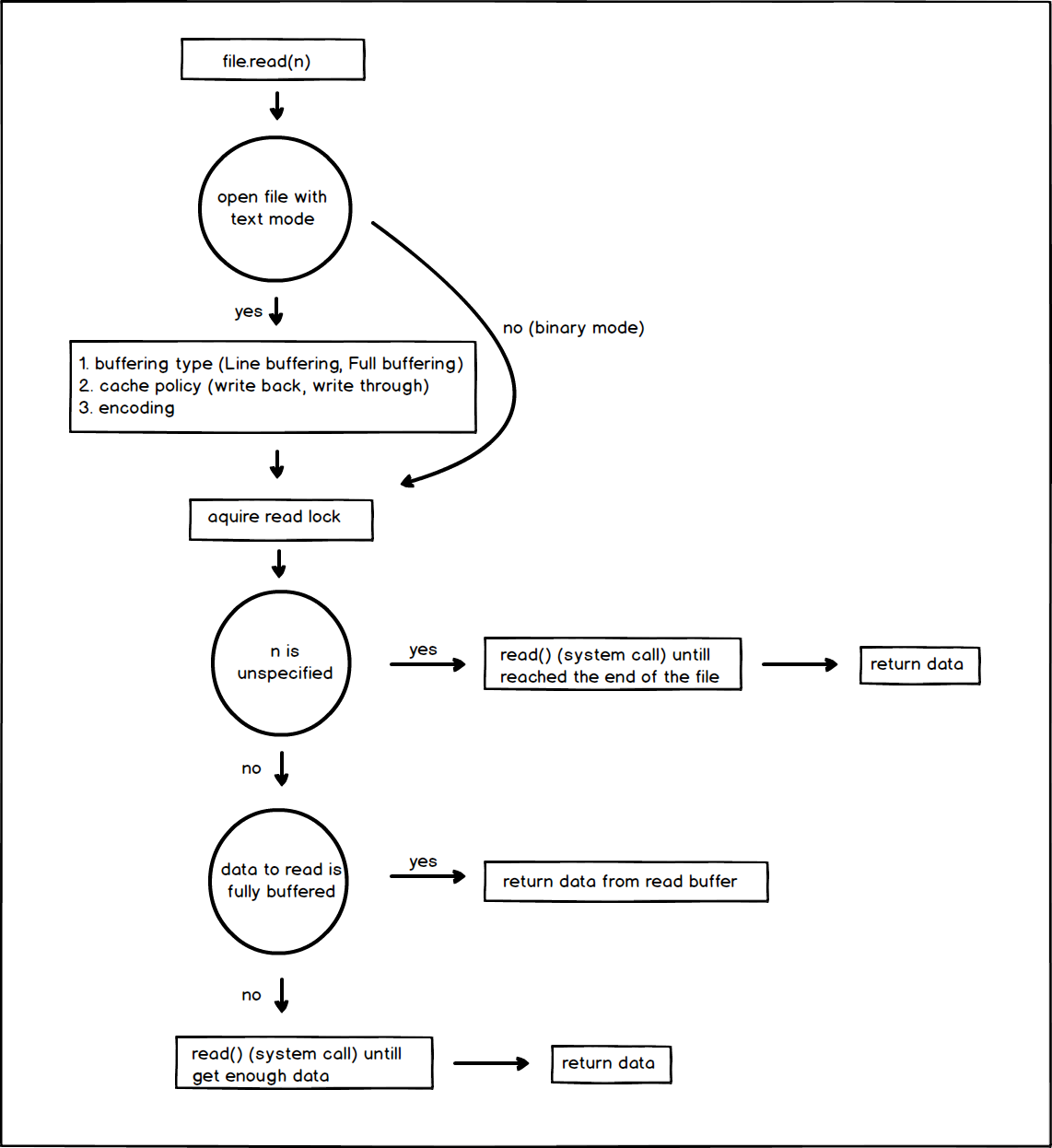
Text I/O and Binary I/O Write
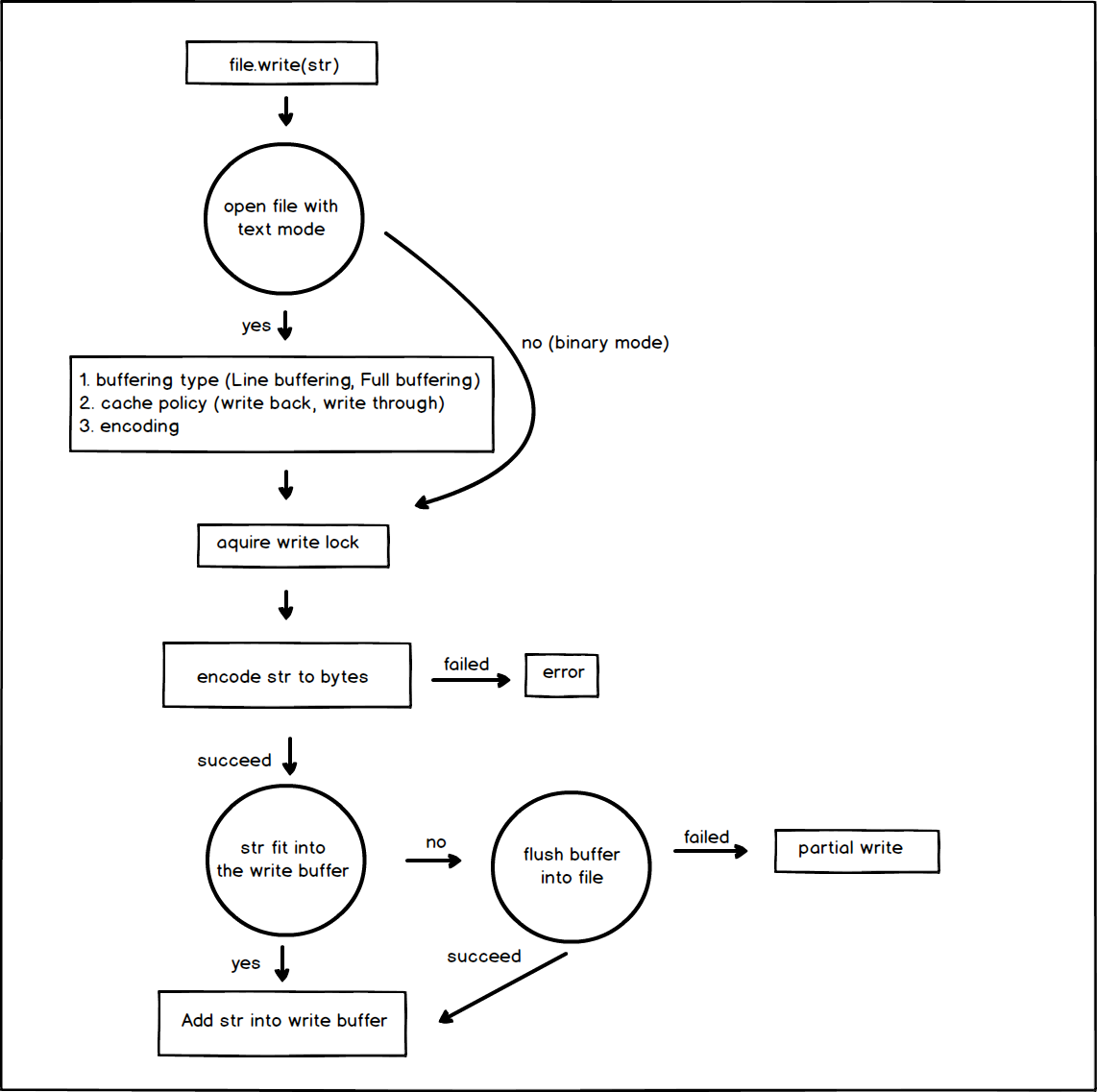
File I/O read and write
The File I/O didn’t use the buffer at all so its process will be easy to understand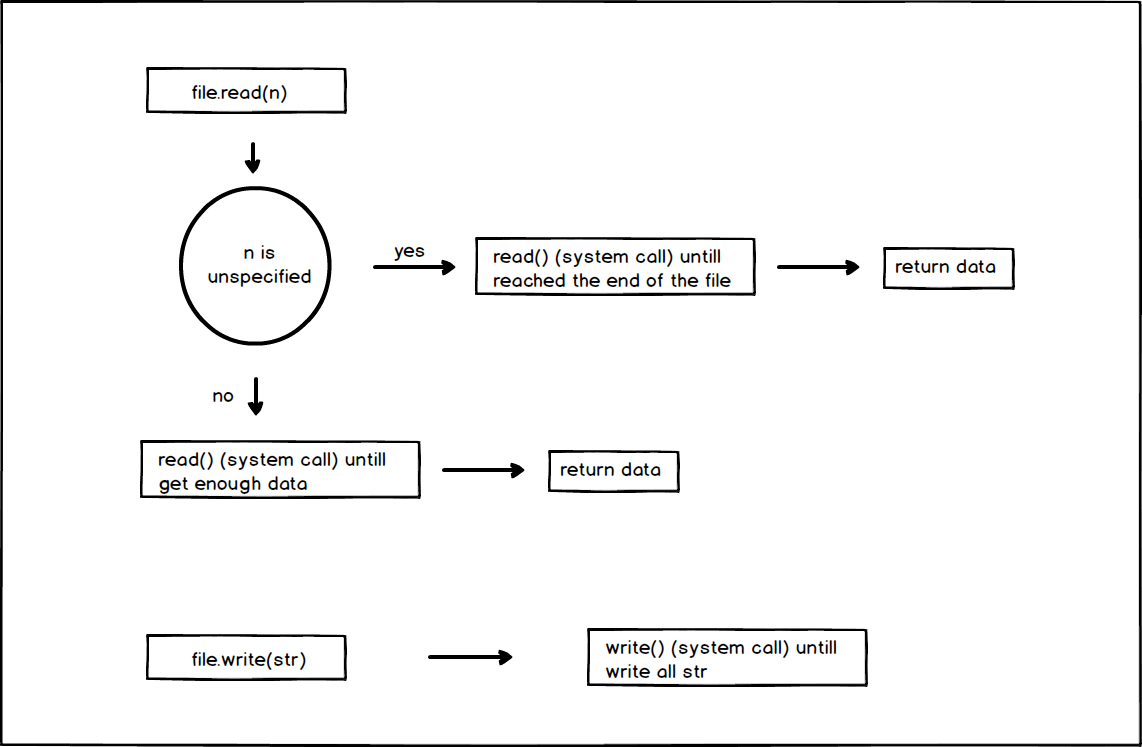
Summary
Both of Text I/O and Binary I/O Write use their buffer, File I/O didn’t’ use any buffer by itself. (although both of them will use kernel buffer). Text I/O just a wrapper on Binary I/O. Their read and write process is quite similar.